• Identify the components for memory
management and persistence in the SAP HANA database architecture
Daemon- Starts all other processes and keeps them running
• Index server- The main database process- Data loads,
queries, calculations, and so on- Provides the embedded statistics service•
Name server- Knows DB Landscape- Knows data distribution
• Preprocessor- Feeds unstructured data (for example,
text documents) into SAP HANA
• Compile Server- Performs the compilation of stored
procedures and programs
• XS-Engine- Web service component, sometimes termed
“application server”
• SAP Web Dispatcher- Entry point for HTTP(s) requests
• SAP start service- Responsible for starting and
stopping the other services
statistics service:
·
collects and evaluates information about status,
performance, and resource consumption from all components belonging to the
system
internal monitoring
infrastructure
·
monitor the status of the system and its
services and consumption of system resources
Statistics
server
·
The statistics server runs as a separate server
process. It is an enhanced index server with a monitoring extension on top.
Statistics
service
·
The statistics service does not run as a
separate server process (statisticsserver). It is implemented as an embedded
service in the master index server
External Interfaces
·
SQL, MDX, and Web interfaces allow clients to
connect and communicate with the SAP HANA database
Request
Processing / Execution Control
·
Depending on the interface and the statement
different components for processing can be invoked, for example, SQL Script
implementations are executed within the so-called Calculation Engine.
Relational Engines
·
The table data in SAP HANA is kept in two different
relational stores:
·
Row Store and Column Store
·
Each of these stores shows substantial
differences with regard to the main memory management
Storage
Engine and Disk Storage
·
achieve consistency and persist changes durably
·
a Storage Engine with Page Management and Logger
is used. This ensures that the database can be restored to the most recent
committed state after a restart and that transactions are either completely
executed or completely undone.
·
Disk Storage is divided in Data Volumes and Log
Volumes.
·
changes need to be written to the log area
before a successful commit of a transaction (synchronous writing)
·
the data area contains the complete main memory
content at a specific point in time and is written asynchronously.
Persistence
Data:
·
SQL data and undo log information
·
Additional HANA information, such as modeling
data
·
Kept in-memory to ensure max performance
·
Write process is asynchronously
Log:
·
Information about data changes (redo log)
·
Directly saved to persistent storage when
transaction is committed
·
Cyclical overwrite (only after backup)
Savepoint:
·
Changed data and undo log is written from memory
to persistent storage
·
Automatic
·
At least every 5 minutes (customizable)
·
Data changes such as insert, delete, and update
are saved on disk immediately in the logs (synchronously). This is required to
make a transaction durable. It is not necessary to persist the complete data,
but the transaction log can be used to replay changes after a crash or database
restart.
·
In customizable intervals (standard: every five
minutes) a new savepoint is created, that is, all of the pages that were
changed are refreshed in the data area of the persistence.
• Describe
the SAP HANA memory usage and allocation behavior
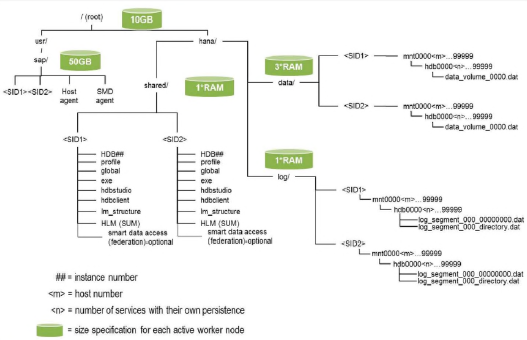
Data Volumes
·
Located in file systems
·
Growing until disk or LUN is full
·
Logical volume Manager: needed on OS level to
extend the file system
·
Growing with number of data volumes
·
PageSizes (4kb, 16k, … 16MB) which are arranged
in superblocks of 64MB
Ext3:
·
Limitation is 2TB
SAP HANA:
·
Automatically
creates additional files if existing files in a data volume located in an ext3
file system reach the 2 TB limit
·
Allows
usage of ext3 file system with larger memory implementation per host
(especially ERP single host systems)
·
No implication to backup, recovery, and so on.
·
Monitoring:SELECT
* FROM PUBLIC.M VOLUME FILES
Shadow Paging Concept
·
write operations write to new physical pages and
the previous savepoint version is still kept in shadow pages
·
if a system crashes during a savepoint
operation, it can still be restored from the last savepoint.
Savepoint Phases:
·
Very short
·
Acquire lock to prevent modification of pages
·
Determine log position
·
Remember open transactions
·
Copy modified pages and trigger write
·
Increase savepoint version
·
Release lock
Redo (log) entries
·
Written synchronously
·
Changed data in data volume is periodically
copied to disk in a savepoint operation
Savepoint
operation:
·
Db flush all changed data from memory to the
data volumes
Data in savepoint
·
represents a consistent state of the data on
disk and remains so until the next savepoint operation has been completed
Savepoint
triggers:
·
databackup, db shutdown/restart
· SAP database holds the bulk of its data in memory for maximum performance, but still uses persistent storage to provide a fallback in case of failure. The log is capturing all changes by database transactions (redo logs)
· Data and undo log information (part of data) are automatically saved to disk at regular savepoints
· The log is also saved to disk continuously and synchronously after each COMMIT of a database transaction (waiting for end of disk write operation).
· After a power failure, the database can be restarted like a disk-based database:- System is normally restarted (“lazy” reloading of tables to keep the restart time short)- System returns to its last consistent state (by replaying the redo log since the last savepoint
· allows restoring the database to the last committed state.