2) DXC (Direct Extractor connection)
3) Flat files
4) Data Services
5) Hana inbuilt EIM( Enterprise Information Management) tools
1) SLT; provides real time data to the customer. Real time data is loaded to HANA from SAP or NON-SAP source systems
architecture:


The difference between the two source systems is that the top picture is a non-abap source system, so SLT is downloaded into another server in order to transfer/ transform and write the new data to the new SAP system using a DB connection.
In a SAP source system you can download the SLT into the SAP source system and transform/write and transfer the information into another SAP source system.
What are the main components of SLT?
1) Logging tables
2) Read modules
3) control Module(Transformation)
4) Write Module
1) used to capture the changed/new records from application tables since last successful replication to HANA.
2) used to read the data from application tables for initial loading and convert the cluster type tables into transparent.
3) used to perform small transformation on the source data. Data from here will be moved to write tables.
4) write the data to HANA system.
Replicate data from SAP source to HANA:
2 Steps
1) Create schema in SLT using the transaction code LTR
2) Replicate the tables of source system to HANA Studio
New --> new schema in LTR(connection b/t the source and target system

Enter schema name, replay jobs( depends on background jobs available in our system)
- In this section we need to select a ‘Source System’, source system can either be SAP or Non-SAP.
- If Source is SAP, then we need to provide a RFC connection Name.
- If Source is Non-SAP, then we have to provide authentication parameters based the type of Data Base.
- Below are the different types of data bases that are currently supported in Non-SAP case by SLT.

Parameters required for connection auth: UN, PW, Host name, instance.
TableSpace Assignment:
-DB size for logging table is mentioned in 'Table Space Assignment'

Replication:
-Real time or scheduled load based on time or interval
Once all the settings are maintained click on ‘OK’ to create a new schema in SLT.
The roles that are created are
- <SCHEMA_NAME>_DATA_PROV
- <SCHEMA_NAME>_POWER_USER
- <SCHEMA_NAME>_USER_ADMIN
- <SCHEMA_NAME>_SELECT
The procedures that are created are
- RS_GRANT_ACCESS
- RS_REVOKE_ACCESS
The tables that are created are
- DD02L
- DD02T
- RS_LOG_FILES
- RS_MESSAGES
- RS_ORDER
- RS_ORDER_EXT
- RS_SCHEMA_MAP
- RS_STATUS
- Once our schema is created, we can go ahead and replicate source system tables into our HANA database.
- For this we have to open our SAP HANA Studio and click on “Data Provisioning” in Quick view as shown below.
- Upon clicking we are navigated to the below screen where we have different options to perform real-time replication.

Activities for real time replication:
- Load
- Replicate
- Stop Replication
- Suspend
- Resume
1) load all the data from source to HANA. Logging tables will not be created in this and real-time replication is not done.
2) This option is used to have real-time replication with historical data. All the data is loaded to HANA and logging tables will be created source for real-time replication.
3) Replication is stopped for the table and logging tables will be deleted in source system.
4) Replication is stopped for the table but logging tables will be there in source system
5) Resume: Resume the replicaiton for suspended tables.
To add a new table for loading or replication, click on ‘Load’ or ‘Replicate’.
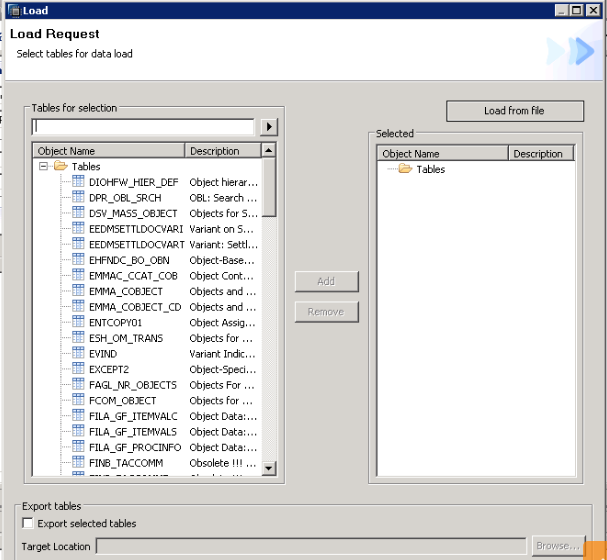
CLick on the required field and press finish.
Jobs in SLT:
Master Job(monitoring job) - IUUC_monitor <MT_ID>:
Every 5 seconds, the monitoring job checks in the SAP HANA system whether there are new tasks and, if so, triggers the master control jobs. It also deletes the processed entries (tasks) from table RS_ORDER and writes statistics entries into table RS_STATUS (in the relevant schema in the SAP HANA system).
Master Controller Job - IUUC_REPLIC_CNTR_<MT_ID>: scheduled on demand; responsible for:
-create database triggers and logging tables in the source system
-creating synonyms
- writing new entries in admin tables in SLT server when a new table is loaded/replicated
Data Load Job – DTL_MT_DATA_LOAD_<MT_ID>_<2digits>: This job should always be active. If the job does not complete successfully, the master controller job restarts it.
This job is responsible for:
- Loading data (load)
- Replicating data (replication)
- Changing status flag for entries in control tables in the SAP LT Replication Server
Migration object definition job - IUUC_DEF_MIG_OBJ_<2digits>: This job defines the migration object of a specific table(that you choose to load/replicate), which is the fundamental object for LT replication.
Access Plan Calculation Job - ACC_PLAN_CALC_<MT_ID>_<2digits>: This job calculates the access plan of a specific table(that you choose to load/replicate) , and the access plan is used for data load or replication. The access plan calculation should finish quite quickly with large tables.
Number of data transfer jobs VS the available BGD work processes:
In SLT Replication Server each job occupies 1 BGD work process. For each configuration, the parameter Data Transfer Jobs restricts the max number of data load jobs for each mass Transfer ID (MT_ID)
In total, a mass transfer ID (MT_ID) requires at least 4 background jobs to be available:
- One monitoring job (master job)
- One master controller job
- At least one data load job
- One additional job either for the migration objects definition, access plan calculation or to change configuration settings in the Configuration & Monitoring Dashboard.
No comments:
Post a Comment